In den vergangenen Beiträgen der Themenreihe „KI in der Bildung“ haben wir uns bereits damit auseinandergesetzt, was KI eigentlich ist, welche Voraussetzung für die Etablierung von KI benötigt werden, wie es um KI in der nationalen und internationalen Politik steht und welche Anwendungsmöglichkeiten KI für Schulen und Hochschulen bereithält. Darauf aufbauend soll es in diesem Beitrag einerseits darum gehen, wie KI lernt und andererseits darum, wie der Mensch von und mit KI lernen kann. Dabei wollen wir insbesondere auf das schulische Lernen bzw. Lernverhalten und Motivation eingehen.
Was noch vor wenigen Jahren als Science-Fiction galt, hält heute in Form von intelligenten Sprachsystemen oder der Navigation über das Smartphone Einzug in unseren Alltag. Die dabei verwendeten Technologien werden zusehend besser und entwickeln sich stets weiter. Im Bereich der künstlichen Intelligenz sind es allen voran das Maschinelle sowie das Tiefe Lernen, auch bekannt als „Deep Learning“, die die digitale Entwicklung vorantreiben. Doch was versteht man eigentlich unter diesen Begriffen und inwiefern hängen sie miteinander zusammen? Darum soll es in dem ersten Teil unseres Beitrags gehen.
Der digitale Fortschritt macht auch vor dem Bildungssektor nicht halt. Heutzutage werden digitale Lernformate wichtiger denn je. Obwohl auch das Bildungssystem das individuelle Lernen als Schlüssel zu einer modernen und integrativen Gesellschaft betrachtet, berücksichtigen viele Lernumgebungen die dafür notwendigen, individuellen und adaptiven Lernprozesse nur in begrenztem Maße. Daraus resultiert die Frage, wie sichergestellt werden kann, dass Schüler*innen individuell zugeschnittenen Lernstoff erhalten.
An diesem Punkt kommen Maschinelles- und Tiefes Lernen ins Spiel. Ihre Algorithmen ermöglich es, die mithilfe von Sensoren gesammelten Daten auszuwerten und somit das Lernverhalten sowie den kognitiven Zustand der Lernenden zu erfassen. Davon ausgehend können dann individuelle Vorschläge zur Erhöhung des Lernerfolgs gegeben werden. In dem zweiten Teil dieses Beitrags gehen wir, anhand eines Vokabeltest, darauf ein, wie der Lernprozesse mithilfe von KI individualisiert werden kann. Außerdem möchten wir auf dieser Grundlage einige Chancen des Lernens mithilfe digitaler Medien aufzeigen, besonders im Hinblick auf die Motivation der Lernenden.
Maschinelles Lernen
Smarte Lösungen für Probleme werden heute kaum noch manuell programmiert. Bei einem Smartphone mit mehr als zehn Millionen Codezeilen wäre dies auch eine sehr mühselige Aufgabe. Stattdessen wird die Fähigkeit des Lernens programmiert. Diese aktuellen Entwicklungen auf dem Gebiet der KI markieren einen Paradigmenwechsel.
Maschinelles Lernen stellt in diesem Zusammenhang ein grundlegendes Teilgebiet der künstlichen Intelligenz dar. Es zielt darauf ab, Maschinen und Systeme zu entwickeln, die ohne die genaue Programmierung eines konkreten Lösungswegs, automatisiert sinnvolle Ergebnisse liefern. Die speziellen Algorithmen erlernen dabei aus vorliegenden Beispieldaten Modelle, die dann auch auf neue Daten angewendet werden können. Dabei gilt: Je größer die Datenmenge, auf die die Algorithmen zugreifen können, desto mehr lernen sie. Entsprechend kann KI sich selbst nur weiterentwickeln, wenn das Maschinelle Lernen als Unterdisziplin ebenfalls Fortschritte verzeichnet. Zwar muss auch beim Maschinellen Lernen weiterhin der Mensch programmieren, doch programmiert er nicht mehr die fertigen Lösungen. Stattdessen entwickelt er Programme, die mithilfe von Trainingsdaten die Lösung selbst erlernen.
Beispiele für den Einsatz solcher Systeme sind die personalisierten Produktempfehlungen bei Amazon, die Gesichtserkennung bei Facebook sowie Vorschläge für die schnellste Route bei Google Maps.
Bezogen auf das Maschinelles Lernen unterscheidet man grundsätzlich drei Methoden: Überwachtes Lernen, nicht-überwachtes Lernen und bestärkendes Maschinelles Lernen. Die beiden ersten angebrachten Formen des Lernens werden unter dem Punkt „Methoden“ bzw. „Deep Learning“ näher ausgeführt.
Bestärkendes Maschinelles Lernen
Diese Form des Maschinellen Lernens braucht kein Ausgangsdatenmaterial, um das lernende System zu trainieren. Das Wissen entsteht stattdessen durch viele verschiedene Simulationsläufe. Dabei werden Lösungen und Strategien auf der Grundlage von erhaltenen Belohnungen generiert. Dieses bestärkende Lernen ist von allen angebrachten Methoden dem Lernen des Menschen am ähnlichsten.
Deep Learning
Die größten KI-Erfolge basieren derzeit auf Neuronalen Netzen, auch „Deep Learning“ oder „Tiefes Lernen“ genannt. Beispielsweise wären moderne Übersetzungs- und Bilderkennungssysteme ohne Neuronale Netzte nicht denkbar.
Als „Deep Learning“ bezeichnet man ein Teilgebiet des Maschinellen Lernens, welches mit eben diesen Neuronalen Netzen arbeitet. Sie verarbeiten die Eingangsinformationen in mehreren Schichten und stellen am Ende das Ergebnis bereit.
Beispiele für den Einsatz von Neuronalen Netzen finden sich in der Industrie bei der Qualitätskontrolle, in der Robotersteuerung oder der Kapazitätsplanung. Auch das Marketing nutzt Neuronale Netze, um beispielweise, um Zielgruppen zu bestimmen und Konsumanalysen durchzuführen. Weiterhin unterstützen Neuronale Netze KI-Anwendungen beim Dateimanagement sowie der Spracherkennung. Im alltäglichen Leben finden Neuronale Netze Anwendung bei Optimierung von Fahrplänen sowie Ampelschaltungen und nicht zuletzt als das „Gehirn“ hinter Alexa, Siri und Co.
Leider ist das Verständnis der theoretischen Grundlagen des Tiefen Lernens teilweise noch lückenhaft. Daher ist das Erarbeiten dieser theoretischen Grundlagen einer der wichtigsten gegenwärtigen Forschungsschwerpunkte in der KI-Forschung.
Das Netzwerk aus miteinander verbundenen Neuronen simuliert quasi den Aufbau und die Abläufe im menschlichen Gehirn. Auch unser Gehirn besteht aus einer Vielzahl von Neuronen, die untereinander mit Synapsen verbunden sind. Hierbei ist zwischen eingehenden und ausgehenden Verbindungen zu unterscheiden. Über die eingehenden Verbindungen erhält ein Neuron elektrische Signale von einem anderen. Überschreitet die elektrische Ladung eine gewisse Grenze, gibt das geladene Neuron ein elektrisches Signal an andere Neuronen ab. Dieses Zusammenspiel von Milliarden an Neuronen versetzt den Menschen in die Lage, Sinneseindrücke zu verarbeiten und nicht zuletzt zu denken. Auf diesem Prinzip basieren auch künstliche Neuronale Netzwerke, um so Daten erkennen und interpretieren zu können.
Die Neuronen in einem Neuronalen Netz arbeiten in kleinen Datenverarbeitungseinheiten. Sie sind schichtweise angeordnet. Die verschiedenen Schichten wiederum bestehen aus vielen Knotenpunkten. Diese sind äquivalent zu den Neuronen im menschlichen Gehirn.
Zu Beginn müssen die Daten in Zahlenwerte transformiert werden. Denn im Gegensatz zum menschlichen Gehirn verarbeiten künstliche Neuronale Netze ausschließlich numerische Werte und keine elektrischen Reize.
Von der ersten Schicht, der Eingabeschicht, ausgehend leitet jeder Knotenpunkt seinen Wert an alle mit ihm verbundenen Knoten in der Aktivierungsschicht weiter. Die Aktivierungsschicht simuliert biologische Neuronen und entscheidet, ob ein Signal weitergegeben wird und wenn ja, in welcher Höhe es weitergegeben wird.
Um nun aus den vorliegenden Daten zu lernen, erhält jede Knotenverbindung ein Gewicht sowie ein Bias, also ein zusätzliches Neuron mit gleichbleibendem Schwellwert, für die Bewertung und Interpretation von Informationen. Die Bias sind wie flexible Schrauben in einem Netzwerk, die überhaupt erst das Lernen ermöglichen. Wichtige Eingabewerte werden dann durch die Gewichte und die Bias in ihrer Signalstärke verstärkt – eher unwichtige werden abgedämpft. Die Gewichtung wird mithilfe der Verbindung bestimmt und gibt an, wie hoch der Einfluss der Daten auf das Neuron ist: ein positives Gewicht übt auf ein anderes Neuron einen verstärkenden Einfluss aus – ein negatives hingegen hat eine hemmende Wirkung. Beim menschlichen Gehirn geschieht dies durch die „Überladung“ des Neurons mit elektrischer Energie. Je mehr Aktivierungsschichten vorhanden sind, desto genauer kann das Neuronale Netz Informationen filtern und ordnen.
Das gleiche Prozedere wiederholt sich dann zwischen der Aktivierungs- und der Ausgabeschicht. Die Anzahl der Knotenpunkt in der Ausgabeschicht entspricht dabei der Anzahl der Kategorien, in die die Informationen eingeordnet werden sollen.
Von Deep Learning spricht man dann, wenn mehr als eine Aktivierungsschicht existiert. Je mehr Aktivierungsschichten ein Netz aufweist, desto tiefer ist es. Werden weitere Knotenpunkt zu der Aktivierungsschicht hinzugefügt, sodass ein sehr breites Netzwerk entsteht, spricht man vom sogenannten „Wide Learning“. Auf diese Weise lassen sich Neuronale Netze bis zu einem gewissen Grad in ihrer Effizienz optimieren.
Deep Learning lässt sich für überwachtes- und nicht-überwachtes Lernen einsetzen.
Überwachtes Lernen
Beim überwachten Lernen werden Daten klassifiziert, wenn für das Anlernen des Neuronalen Netzes benannte oder „gelabelte“ Daten vorhanden sind. Für ein Datensatz bestehend aus Hunde- und Katzenbildern beispielsweise wäre für jedes Bild die korrekte Bezeichnung, also „Hund“ für Hundebilder und „Katze“ für Katzenbilder, vorhanden.
Nicht-überwachtes Lernen
Wenn keine solch beschrifteten Daten vorliegen, wird das nicht-überwachte Lernen eingesetzt. Hierbei ist das Deep Learning in der Lage, selbstständig ein Clustering der Bilder vorzunehmen. Unter „Clustering“ versteht man die Zuordnung von Bildern anhand von visuellen Merkmalen zu einer Gruppe oder Kategorie. Dem Algorithmus ist dabei, im Gegensatz zum überwachten Lernen, nicht bewusst, dass es beispielsweise Hunde oder Katzen auf den jeweiligen Bildern erkennt. Um die Bilder zu unterscheiden und daraufhin in Gruppen einzuordnen, benötigt die KI zahlreiche Vergleiche dieser Bilder.
Neben diesen beiden Beispielen des überwachten und nicht-überwachten Lernens gibt es noch einige weitere Methoden des Deep Learnings wie die Lineare Regression oder die Dimensionsreduktion.

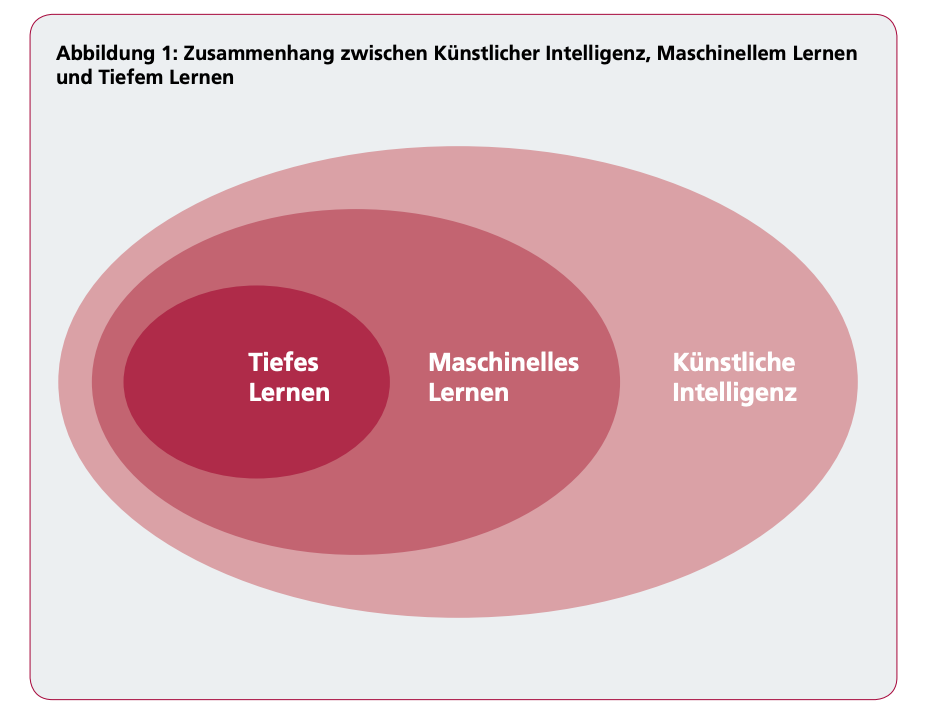
Zusammenhang zwischen KI, Maschinellem Lernen und Deep Learning
Die benannten Begriffe werden häufig nicht trennscharf verwendet. Gemeinsam ist allen, dass sie auf Algorithmen, also eindeutigen Handlungsvorschriften zur Lösung eines Problems, basieren. Künstliche Intelligenz definiert Herausforderungen, die es zu lösen gilt, und entwickelt dazu Lösungsansätze. Beim Maschinellen Lernen wiederum steht das Erlernen im Vordergrund. Das Tiefe Lernen stellt in diesem Zusammenhang derzeit einige der leistungsfähigsten Ansätze des maschinellen Lernens bereit.
Lernen von und mit KI – Analyse von Lernverhalten
Das Lernen mithilfe digitaler Technologien nimmt einen immer größeren Bereich ein – sowohl in der schulischen bzw. universitären Bildung als auch in der betrieblichen Weiterbildung. Die digitalen Technologien eröffnen bisher ungekannte Möglichkeiten. Statt eines einfachen Textbuches oder eines Tafelbildes können im Unterricht Musikstücke, Animationen und ganze Videos verwendet werden. Damit geht jedoch die Frage einher, wie aus dieser Fülle neuer Möglichkeiten die optimalen, zur Lernsituation passenden Elemente ausgewählt- und wann diese den Lernenden zum möglichst geeigneten Zeitpunkt zur Verfügung gestellt werden sollen.
Eine allgemeingültige Antwort auf diese Frage gibt es nicht. Schließlich ist das Lernen ein höchst individueller Vorgang. In Anbetracht von beispielsweise zunehmenden Klassengrößen und damit einhergehend von einem verringerten Überblick der Lehrkraft über die Klasse scheint es jedoch durchaus sinnvoll, die vorhandenen Lernkräfte der Schüler*innen mithilfe technischer Mittel zu unterstützen. Allen voran die künstliche Intelligenz ermöglicht es, direkte Einblicke in Vorgänge und Zustände zu gewinnen, die sonst für außenstehende Beobachtende unsichtbar sind. Um solche Zustände messen zu können, wird auf eine Vielzahl an Sensoren zurückgegriffen.
Das Immersive Quantified Learning Lab (iQL) beispielsweise hat eine solche Lernumgebung mit technologiebasierten, interaktiven Kommunikationsmedien erschaffen. Unter der Verwendung von intelligenten Analyse- sowie Machine-Learning-Verfahren sollen dadurch individuelle Unterstützungsmaßnahmen für jede Altersgruppe bereitgestellt werden. Das iQL gibt darüber hinaus Einblick in die neusten Sensoren-Technologien sowie wie diese in Lern- und Arbeitsszenarien verwendet werden können, um den kognitiven Zustand von Versuchspersonen zu messen und um Bedingungen zu schaffen, die die kognitive Belastung verringern und damit die Effizienz erhöhen.
Beispiel Vokabeltest
Ein Beispiel für die verwendete Sensoren-Technologie ist ein Vokabeltest, der das individuelle Selbstvertrauen der Lernenden anhand deren Blickbewegung erfasst.
Hierbei ist der Eye-Tracker in eine unauffällige, schwarze Sensorleiste direkt unterhalb des Bildschirms angebracht. Er misst zum Beispiel, wie lange Fragen und Antworten gelesen werden, wie oft zwischen Fragen und Antworten hin- und hergeschaut wird oder wie lange der Blick auf einer Antwort bleibt, bis diese angeklickt wird. Basierend auf diesen charakteristischen Mustern kann mithilfe von KI das Selbstvertrauen der Proband*innen bestimmt- und auf dieser Grundlage der Test verändert werden. Beispielsweise können bei Unsicherheiten ähnliche Aufgaben wiederholt angezeigt werden.
Um Dinge wie das Selbstvertrauen oder Verständnis von Teilnehmenden vom Computer ermitteln zu lassen, muss mittels KI bzw. dem Maschinellen- sowie dem Tiefen Lernen ein Klassifizierer trainiert werden. Dazu werden zunächst mit diversen Sensortechnologien Trainingsdaten von den Lernenden erhoben. Basierend darauf können dann Algorithmen Muster in den Daten ermitteln und charakteristische Zusammenhänge erkennen, wie in dem Abschnitt „Neuronale Netze“ bereits erklärt. Auf diese Weise kann der Klassifizierer anschließend auf Daten unbekannter Personen angewendet werden und somit korrekte Vorhersagen über deren Lernzustände treffen.
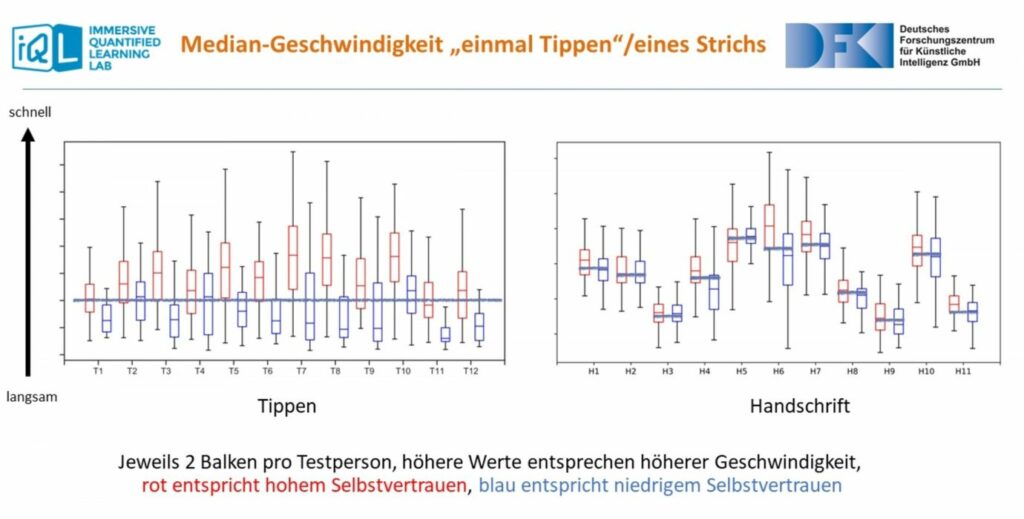
Auf den beiden Bildern sieht man Messdaten, die während zweier Vokabeltests erhoben wurden. Bei dem „Tippen“-Test links erhielten die Teilnehmenden Fragen auf ihr Smartphone und mussten die Antworten eingeben. Bei dem rechten „Handschrift“-Test hingegen wurden die Fragen auf einem Computer mit Touchscreen angezeigt und die Teilnehmenden mussten ihre Antworten mithilfe eines speziellen Stifts namens „Stylus“ auf den Bildschirm schreiben. Die Darstellungen zeigen jeweils ein erfasstes Feature: Beim „Tippen“-Test wurde die mittlere Tippgeschwindigkeit auf dem Bildschirm-, beim „Handschrift“-Test die mittlere Strichgeschwindigkeit gemessen.
Bezogen auf das Tippen reicht es aus, das Feature der Tippgeschwindigkeit zu betrachten, um zwischen Personen mit hohem und niedrigem Selbstvertrauen unterscheiden zu können. Im Falle des „Handschrift“-Test hat sich gezeigt, dass die Schreibgeschwindigkeit stark von der Person abhängt, jedoch nicht unbedingt im Zusammenhang mit dem Selbstvertrauen der betreffenden Person steht. Die Schreibgeschwindigkeit als einzige Eigenschaft heranzuziehen, würde für eine zuverlässige Messung nicht ausreichen. Eine korrekte Vorhersage wäre dann möglich, wenn man weitere Features beim Schreiben wie Winkel, Absetzen des Stifts und den Druck berücksichtigen würde.
Dieses Beispiel hat gezeigt, dass sich mithilfe moderner Technik durchaus das Lernverhalten von Probanden erfassen lässt. Die durch KI gewonnen Daten können in diesem Zusammenhang analysiert werden, um somit kognitive Zustände zu bestimmen, Lernprobleme zu identifizieren und daraufhin individuelle Lernvorschläge zu machen.
Lernen von und mit KI – Digitales Lernen motiviert
Das Lernen mithilfe neuster Technologien individuell zu gestalten, ist ein wesentlicher Schwerpunkt der KI-Forschung im Bildungssystem. Dabei wird jedoch ein weiteres wichtiges Hauptaugenmerk oftmals vernachlässigt – die Motivation, die digitale Medien mit sich bringen können, für Lernprozesse sinnvoll zu nutzen. Die Bereitschaft und Motivation zum lebenslangen Lernen sind vor allem in unserer digitalen Gesellschaft, die sich ständig und rasant wandelt, von großer Bedeutung. Besonders Kinder haben einen angeborenen Wissensdrang und sind von sich aus motiviert, Neues zu lernen. Doch in der Schule zeichnet sich oftmals ein ganz anderes Bild ab: da können die Lehrkräfte von motivierten Schüler*innen nur träumen und müssen selbst so einiges auffahren, um die Kinder zum (motivierten) Lernen zu bewegen. Digitale Medien können an dieser Stelle unterstützen und das leisten, was die Schule oft nicht schafft: Kinder fesseln und begeistern. Die digitale Welt eröffnet unzählige Möglichkeiten, Wissen interaktiv und ansprechend zu gestalten. So wird ein spannender Zugang zum Lernen geschaffen. Denn…
Digitale Medien bestechen allen voran durch ihre Multimediafähigkeit. Wie eine Zirkusvorführung sind sie somit in der Lage, Kinder zu fesseln und sie in ihren Bann zu ziehen. Diese Eigenschaft lässt sich doch prima auf das Lernen übertragen und nutzen! Der Schulstoff kann auf diese Weise für die Lernenden lebensnah und greifbar aufbereitet werden zum Beispiel in Form von Abenteuerwelten, die in eine spannende Geschichte eingebettet sind. Dies bezeichnet man auch als „Gamification-Ansatz“. Damit wird der dem Menschen angeborenen Wissensdrang angestachelt. Die Kinder begreifen Dinge automatisch in ihrer Ganzheit und wollen sie in der Abenteuerwelt anwenden. Dies ist beispielsweise der Fall, wenn sie mithilfe der richtigen Antworten eine Schatztruhe öffnen. Diese interaktiven und multimedialen Lerninhalte machen deutlich mehr Spaß und befeuern damit die Lernmotivation.
Das wichtigste ist natürlich trotzdem der Lernerfolg. Dieser wird begünstigt durch die vielen Sinne, die während des Lernprozesses angesprochen werden. Die Einbindung von Animationen, Videos, Audiodateien und interaktiven Elementen in Online-Lernprogrammen hilft dabei, Wissen lebendig zu machen und es im Gehirn nachhaltig zu verankern. Wird der Schulstoff in den Abenteuerwelten jenseits der bekannten Aufgabenstellungen angewendet, durchdringen Schüler*innen das Wissen und üben sich nebenbei in der Transferleistung.
Neben der Multimediafähigkeit der digitalen Medien bestechen diese weiterhin dadurch, dass sie individuelles Lernen ermöglichen. Dies ist von großem Vorteil, denn jeder Mensch hat andere Stärken und Schwächen, ein individuelles Lerntempo sowie spezifische Interessen. Die große Fülle an Online-Materialien bietet passende Inhalt für alle Lernenden, damit sie sich ganz individuell mit den unterschiedlichen Themen beschäftigen können. Sie können den Lernstoff, abseits vom Schuldruck, in Ruhe wiederholen oder ein Thema, das sie besonders interessiert, vertiefen.
Außerdem ist das Online-Lernen zeit- und ortsunabhängig, sodass es auf individuelle Tagesabläufe und Termine abgestimmt werden kann. Darüber hinaus können die Online-Inhalte aktualisiert sowie erweitert werden und sich somit immer den neusten Erkenntnissen anpassen.
Digitale Technologien etablieren sich blitzschnell in der Familie und können durchaus den Alltag erleichtern oder einfach nur Spaß machen. Und nicht nur wir Erwachsenen erfreuen uns daran, wenn wir Alexa bitten, „Oh happy day“ zu spielen. Warum sollte man diese Faszination für neue Medien nicht auch beim Lernen nutzen?
In diesem Zusammenhang spricht man vom sogenannten „Damoklesschwert Lernen“. Darunter versteht man die Fähigkeit von Online-Lernangeboten, Kinder derart zu begeistern, dass sie sich freiwillig mit dem Schulstoff beschäftigen. Vor allem Motivationselemente wie ein eigener Avatar sowie Punkte- und Levelsysteme wecken den Spieltrieb bei Kindern, der dann auf sinnvolle Weise mit dem Lernstoff verbunden wird. Gleichzeitig erfahren Kinder etwas über den sinnvollen Umgang mit digitalen Technologien. Sie entwickeln sich von passiven Konsumenten hin zu aktiv Gestaltenden, die digitale Medien clever für bestimmte Ziele einsetzen. Darüber hinaus lernen sie mit und über neue Medien, wie sie KI für sich nutzen können.
Fazit
KI mit ihren Unterdisziplinen Maschinelles- und Tiefes Lernen eröffnet nicht nur Unternehmen viele neue Möglichkeiten des technologischen Fortschritts. Auch in Zukunft werden diese Technologien viele weitere Gesellschafts- sowie Wirtschaftsbereiche und nicht zuletzt den Bildungssektor erobern.
Der Einsatz von KI im Bildungsbereich bringt unzählige Chancen mit sich wie die Individualisierung von Lernprozessen und die Motivation zum Lernen. Um dies jedoch zu gewährleisten, brauchen die Algorithmen riesengroße Datenpools, aus denen sie ihre Informationen entnehmen. In diesem Zusammenhang werden Probleme mit dem Datenschutz erkennbar. Weiterhin darf der Einsatz von digitalen Medien immer nur dann erfolgen, wenn er auch wirklich sinnvoll ist. Die aufgezeigten Technologien sind dazu da, Lehrkräfte zu unterstützen und nicht zu ersetzen. Eine solche Unterstützung der Lehrenden ist jedoch nur dann möglich, wenn diese einerseits offen gegenüber den neuen Technologien sind und andererseits selbst über gewisse digitale Kompetenzen verfügen.
Klar ist und bleibt: Der Mensch definiert und legt die Anwendungsgebiete von KI fest. Der Grad an Autonomie des Systems darf dabei nicht nur der technischen Limitierung der KI unterliegen. Auch rechtliche und ethische Rahmenbedingungen sowie die Forderungen nach Datensicherheit müssen hier die entsprechenden Grenzen setzen.
Abbildung 1
Quelle: Tsoutis, Stefanos: Deep Learning – Neuronale Netze und mehr. link Stiftung Niedersachsen 2019. https://www.link-niedersachsen.de/blog/blog_technik_wissenschaft/deep_learning
Abbildung 2
Quelle: Kersting, Kristian/Tresp, Volker: Maschinelles und Tiefes Lernen. Der Motor für „KI made in Germany“. München: Lernende Systeme – Die Plattform für Künstliche Intelligenz 2019. S. 5. https://www.tu-darmstadt.de/media/daa_responsives_design/03_forschung_medien/forschungskompetenz/ki_forschung_1/AG1_Whitepaper_280619.pdf
Abbildung 3
Quelle: Grossman, Dr. Rer. Nat. Nicolas: Lernen mit KI – Analyse von Lernverhalten und adaptive Medien. Link Stiftung Niedersachsen 2020. https://www.link-niedersachsen.de/blog/blog_technik_wissenschaft/iql_lernen_mit_ki
- https://www.wissenschaftsjahr.de/2019/neues-aus-der-wissenschaft/das-sagt-die-wissenschaft/treiber-der-aktuellen-ki-entwicklung/
- https://www.tu-darmstadt.de/media/daa_responsives_design/03_forschung_medien/forschungskompetenz/ki_forschung_1/AG1_Whitepaper_280619.pdf
- https://www.vdi.de/news/detail/und-am-anfang-war-der-algorithmus
- https://www.link-niedersachsen.de/blog/blog_technik_wissenschaft/deep_learning
- https://www.link-niedersachsen.de/blog/blog_technik_wissenschaft/iql_lernen_mit_ki
- https://www.codingkids.de/anfangen/motiviert-lernen-warum-digitales-lernen-die-l%C3%B6sung-ist
